Context
ASR.lab is a systematic evaluation platform for automatic speech recognition (ASR) engines. It enables comparing models from different architectures and organizations — OpenAI, Meta, NVIDIA, Alibaba — under controlled and reproducible acoustic conditions, through a fully declarative configuration interface (YAML).
Architecture
The benchmark pipeline chains configurable stages run as a Cartesian product:
- Audio degradation: applying realistic acoustic conditions (reverb, noise, compression) via VST3 plugins, with named preset management
- Audio enhancement (optional): denoising via
DemucsorDeepFilterNet, applied to the degraded audio - Loudness normalization: grid search across different LUFS levels conforming to the EBU R128 standard
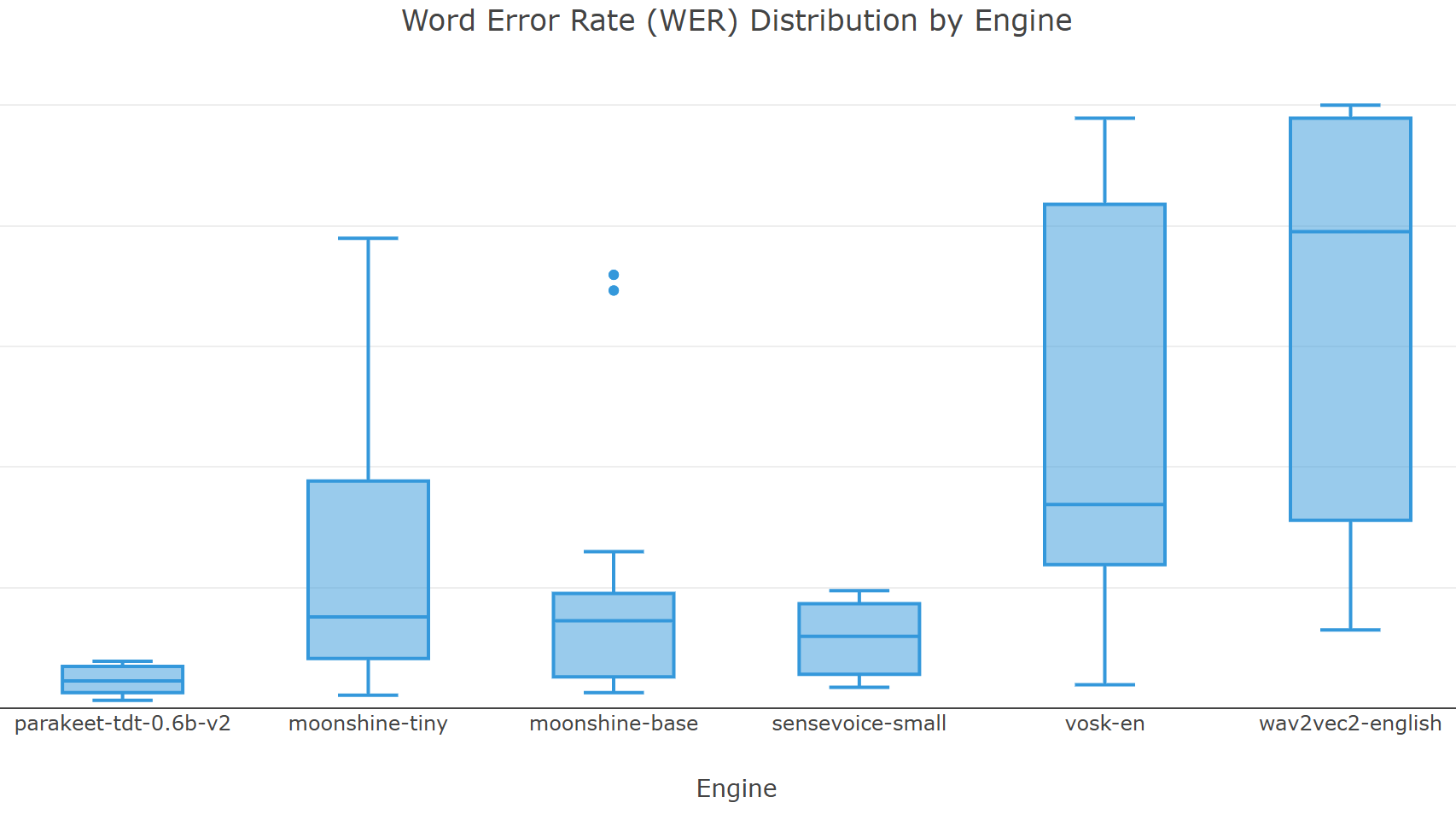
- ASR transcription: processed through all enabled engines (Whisper, Wav2Vec2, NeMo, Vosk, SeamlessM4T, Moonshine, SenseVoice)
- Metrics computation: WER, CER, MER, WIL, WIP — computed twice for each transcription (raw and normalized text), forming an additional grid search dimension
Each combination of degradation × enhancement × normalization × engine generates a distinct entry in the results, enabling exhaustive analysis of the factors affecting recognition performance.
Features
- Multi-engine: 7 supported and tested frameworks — Whisper, Wav2Vec2, NeMo, Vosk, SeamlessM4T, Moonshine, SenseVoice
- Automatic grid search: Cartesian product of all test parameters, configured in YAML
- Interactive reports: self-contained HTML with multi-criteria filters, scatter plots, heatmaps, word-level diffs, and CSV-exportable table — no client-side Pandas/Plotly dependency
- Live demo on Hugging Face Spaces
- Extensible: plugin architecture for adding new engines or metrics
- Open source under MIT license, Python 3.12+, dependency management via
uv
Impact
ASR.lab provides a concrete answer to the question “which ASR engine, under what conditions, for which language?” — a key decision for any large-scale transcription project. By making evaluation reproducible and exhaustive, it provides a solid factual basis for comparing open source solutions and guiding technical choices.