NLP & RAG
SmartWatch
Stable
juin 2025
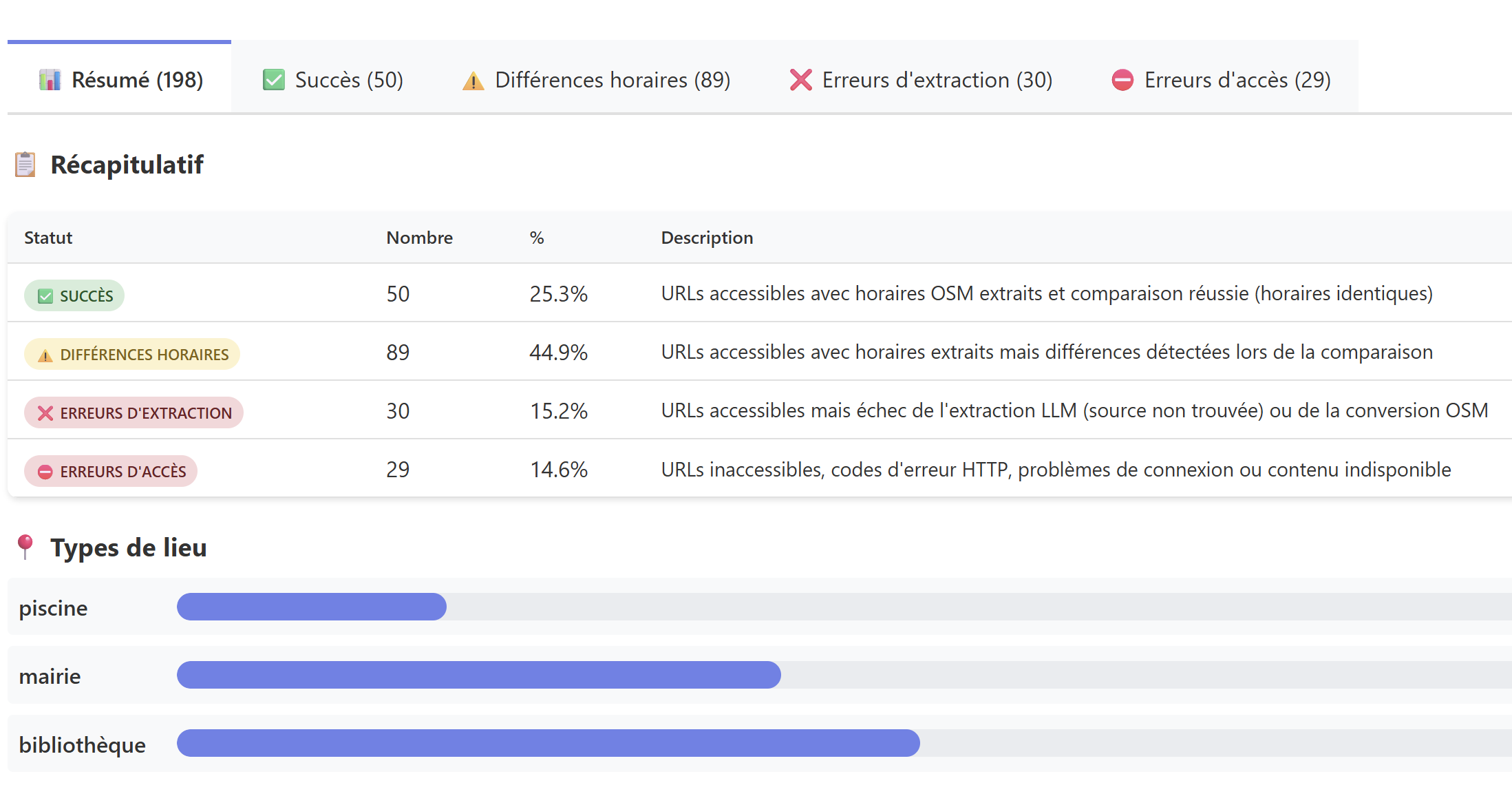
An automated data pipeline for the Metropolis of Lyon that retrieves, extracts, and compares public facility opening hours using semantic filtering and large language models.
Python LLM Playwright Embeddings NLP CodeCarbon Polars SQLAlchemy Jinja2