
Contexte
L’évaluation et le déploiement de systèmes de reconnaissance automatique de la parole (ASR) en environnement de production se heurtent à la grande diversité et variabilité des conditions acoustiques réelles. Les signaux vocaux y sont fréquemment perturbés par le bruit ambiant, la réverbération des pièces, les codecs de compression ou des variations importantes de volume sonore. Choisir le modèle ASR le plus adapté nécessite donc une approche rigoureuse et factuelle afin de mesurer précisément le comportement de chaque moteur face à leurs propres contraintes acoustiques (ex: appels de centres de contacts, réunions, bruits de l’habitacle en automobile) pour trouver le meilleur équilibre entre précision, latence et coûts d’infrastructure.
Objectif
Ce projet avait pour objectif de concevoir et de réaliser une plateforme d’évaluation systématique et automatisée permettant de comparer différents moteurs ASR sous des conditions acoustiques reproductibles et paramétrables. Les livrables attendus comprenaient :
- Un pipeline de traitement audio capable d’appliquer des dégradations acoustiques réalistes, d’exécuter des filtres de débruitage avancés (speech enhancement) et de normaliser le niveau sonore.
- Une couche d’adaptation unifiée facilitant la communication avec différents moteurs ASR locaux et cloud.
- Un système de configuration déclaratif au format YAML permettant de lancer des analyses combinatoires automatiques (grid searches).
- Un tableau de bord interactif et autonome pour analyser, filtrer et exporter les métriques de qualité issues du benchmark.
Démarche
- Architecture déclarative et orchestration : Conception d’un orchestrateur en Python 3.12 qui parse une configuration déclarative YAML pour générer un produit cartésien de scénarios de test.
- Pipeline de traitement audio amont :
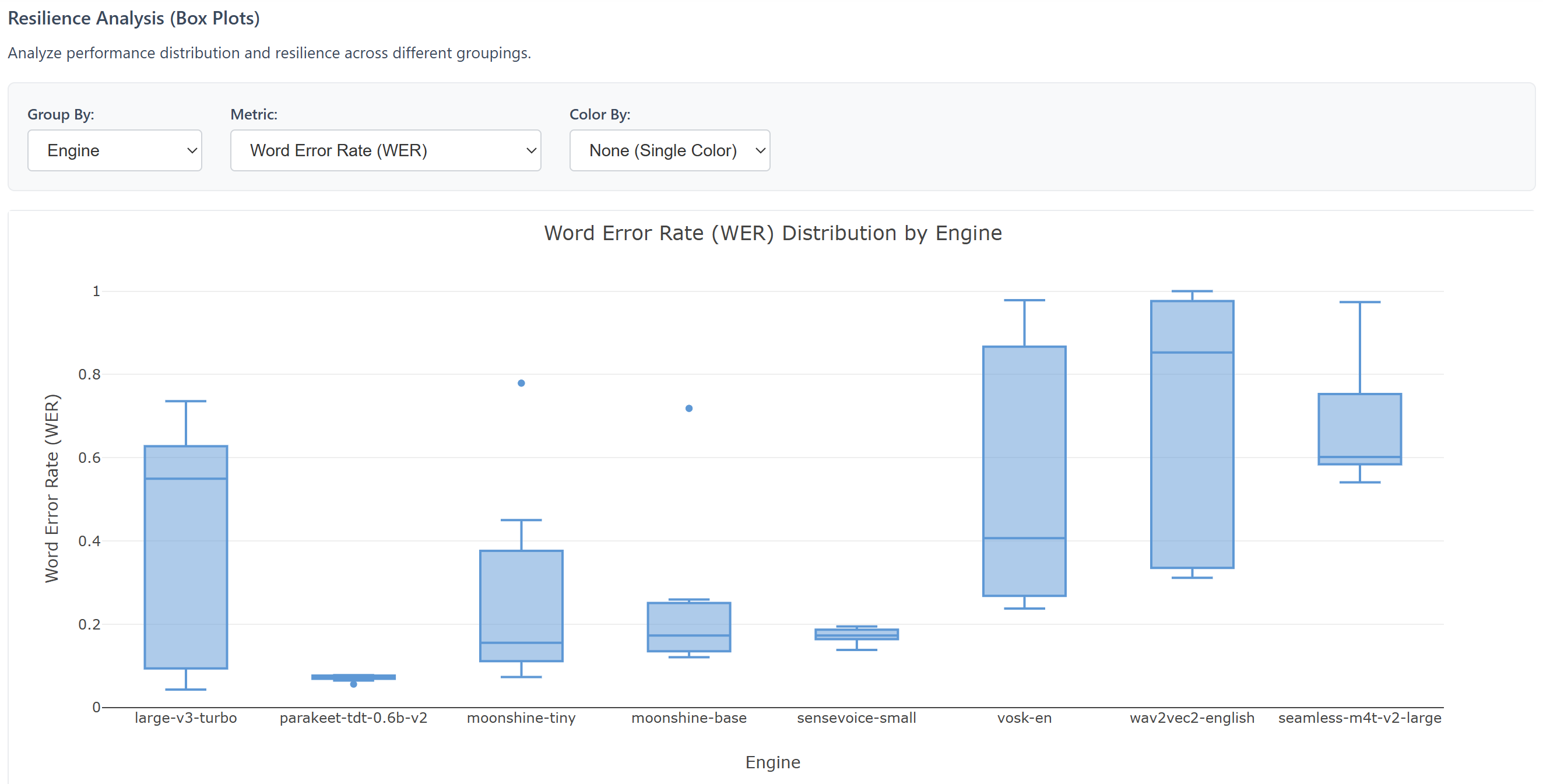
- Dégradation audio contrôlée : intégration de plug-ins audio au format VST3 pour appliquer des filtres réalistes (réverbération, bruits additifs, distorsion, etc.) sur les fichiers audio de référence. Le pipeline permet de tester plusieurs scénarios de dégradations acoustiques pour mesurer le seuil de rupture et donc la résilience de chaque modèle.
- Restauration optionnelle (Speech Enhancement) : branchement optionnel des modèles d’apprentissage profond de débruitage et de séparation de sources
DemucsetDeepFilterNetsur les signaux dégradés, afin d’évaluer l’efficacité de ces pré-traitements sur la reconnaissance vocale. - Normalisation de l’intensité sonore : normalisation automatique à différents niveaux de volume exprimés en LUFS selon la norme de diffusion EBU R128, éliminant les biais de volume sonore lors de la phase de transcription.
- Moteurs de transcription ASR unifiés : développement d’un adaptateur universel unifiant l’accès à 7 frameworks de reconnaissance automatique de la parole :
Whisper(OpenAI / version optimisée Faster-Whisper),Wav2Vec2(Meta via Hugging Face Transformers),NVIDIA Parakeet,Vosk(Kaldi offline),SeamlessM4T(Meta),Moonshine, etSenseVoice(Alibaba).
- Calcul de métriques sur deux formats textuels :
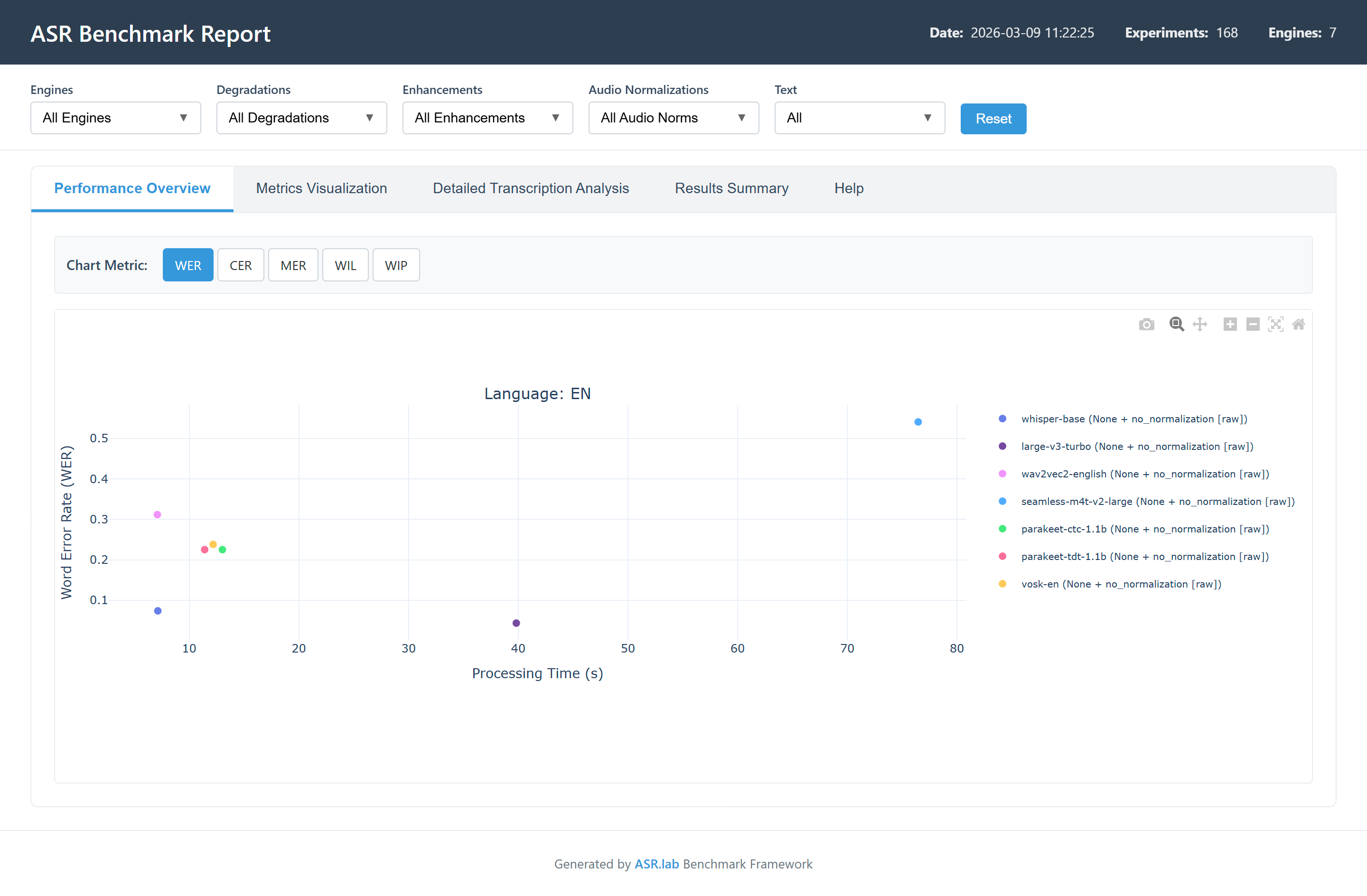
- Calcul des métriques standards de l’industrie : taux d’erreur de mots (WER), de caractères (CER), taux d’erreur d’appariement (MER), information mot perdue (WIL) et préservée (WIP).
- Ces métriques sont calculées sur le texte brut retranscrit, et après application d’un pipeline de normalisation textuelle standardisé (suppression de la ponctuation, normalisation des nombres, mise en minuscule) pour isoler les erreurs d’interprétation phonétique des simples divergences de formatage textuel.
- Génération de rapports autonomes : création d’un module de rendu générant un rapport HTML unique, portable et auto-suffisant. Les visualisations interactives (heatmaps de WER, diagrammes de dispersion, diffs de texte mot-à-mot colorés) sont générées côté client sans dépendance à Plotly ou Pandas, optimisant la rapidité d’affichage et l’usage hors ligne.
Caractéristiques
- 7 frameworks ASR supportés : Whisper, Wav2Vec2, NeMo, Vosk, SeamlessM4T, Moonshine et SenseVoice, exécutables localement.
- Grid search automatique : génération combinatoire complète des scénarios d’évaluation à partir de fichiers YAML.
- Rapports interactifs autonomes : tableau de bord HTML sans dépendances d’exécutions tierces (Pandas/Plotly) côté client, exportable en CSV.
- Extensibilité par plugins : architecture ouverte facilitant l’ajout de nouveaux moteurs de transcription ou de nouvelles métriques d’évaluation.
- Outillage moderne : codebase Python 3.12+, typage statique rigoureux, gestion des dépendances via
uv, licence MIT.
Impact
ASR.lab résout un problème industriel critique en transformant le choix d’un moteur de reconnaissance vocale en une décision purement factuelle et quantifiée :
- Mise en évidence de moteurs résilients : les tests sous contraintes acoustiques croissantes démontrent que si certains modèles (comme
Whisper) excellent sur un signal propre, ils déclinent rapidement sous de fortes perturbations, tandis que d’autres (comme les modèlesNVIDIA Parakeet) s’avèrent extrêmement résilients, conservant un niveau de précision quasi-constant quel que soit le niveau de bruit ou de réverbération appliqué. - Identification fine des biais non acoustiques : Grâce à la coloration mot-à-mot intégrée aux rapports interactifs, l’utilisateur peut visualiser directement la nature des erreurs. On constate ainsi que pour les moteurs les plus performants, une baisse apparente du WER ne provient pas d’une mauvaise reconnaissance acoustique, mais d’écarts de normalisation mineurs (par exemple, un nombre écrit en chiffres au lieu de lettres, ou un mot en majuscules dans l’original et en minuscules dans la transcription).
- Économies de coûts d’infrastructure : aide à identifier si un modèle plus léger pré-traité (par exemple par
DeepFilterNet+Whisper Base) surpasse un modèle géant coûteux non traité (commeWhisper Large-v3), réduisant ainsi les besoins en GPU et le coût total de possession (TCO). - Reproductibilité scientifique : Les benchmarks sont entièrement reproductibles grâce au stockage des configurations YAML, facilitant la non-régression lors du déploiement de nouvelles versions de modèles.