
Contexte
Dans les pipelines RAG (Retrieval-Augmented Generation), la qualité du filtrage sémantique repose sur plusieurs leviers interdépendants : stratégie de découpage du texte (chunking), modèle de représentation vectorielle (embeddings), etc. En pratique, leurs performances varient selon la langue des documents, la taille des segments, le taux de recouvrement et la métrique de similarité retenue. L’absence d’outil d’évaluation systématique conduit à des choix d’architecture souvent empiriques, sans garantie que la configuration retenue soit optimale. ForzaEmbed est né de ce constat : il s’agit d’un projet dérivé de SmartWatch, où le besoin d’optimiser le filtre sémantique a nécessité la création d’un framework d’évaluation dédié.
Objectif
Le défi consistait à concevoir un outil automatisé capable d’explorer de façon exhaustive l’espace des hyperparamètres liés aux embeddings, et d’en restituer les résultats sous une forme visuelle immédiatement interprétable. Le livrable attendu est un framework Python open source, couplé à un moteur de rendu HTML interactif, produisant des rapports autonomes exploitables à la fois par des data scientists en phase de R&D et par des équipes projets devant justifier des choix techniques.
Démarche
Le framework s’organise autour d’un pipeline logiciel structuré en trois composants :
-
Génération de l’espace de recherche (Grid Search) : à partir d’un fichier de configuration YAML, l’outil produit le produit cartésien de tous les hyperparamètres déclarés : modèles d’embedding (sentence-transformers, FastEmbed, API OpenAI ou Mistral), stratégies de chunking (LangChain, raw, semchunk, NLTK, spaCy), tailles de segments (jusqu’à 7 paliers, de 10 à 1000 caractères), taux de recouvrement (0 à 200), métriques de similarité (cosinus, euclidienne, Manhattan, produit scalaire, Chebyshev), et listes de mots-clés thématiques. Les combinaisons impossibles (ex : overlap supérieur à la taille du chunk) sont automatiquement exclues.
-
Exécution parallélisée et cache persistant : Pour chaque combinaison valide, le texte source est segmenté et les embeddings sont calculés via la librairie FastEmbed – qui supporte nativement l’exécution multi-CPU/multi-GPU – complétée par un client HuggingFace pour les modèles additionnels. Une base de données SQLite locale sert de cache persistant : chaque chunk est haché et son vecteur est stocké, ce qui permet de ne pas recalculer les embeddings lors des variations de paramètres externes (par ex. métrique). Les segments sont ensuite évalués par similarité avec les thématiques utilisateur. Avec 7 tailles de chunk × 7 chevauchements × 5 stratégies × 5 métriques × 3 thèmes × 8 modèles (soit ~21 000 combinaisons), ce cache évite des redondances massives.
-
Moteur de rendu autonome : Les résultats sont compilés dans un unique fichier HTML. Un bandeau semi-transparent flottant permet de manipuler les curseurs des hyperparamètres en temps réel. Le rapport intègre :
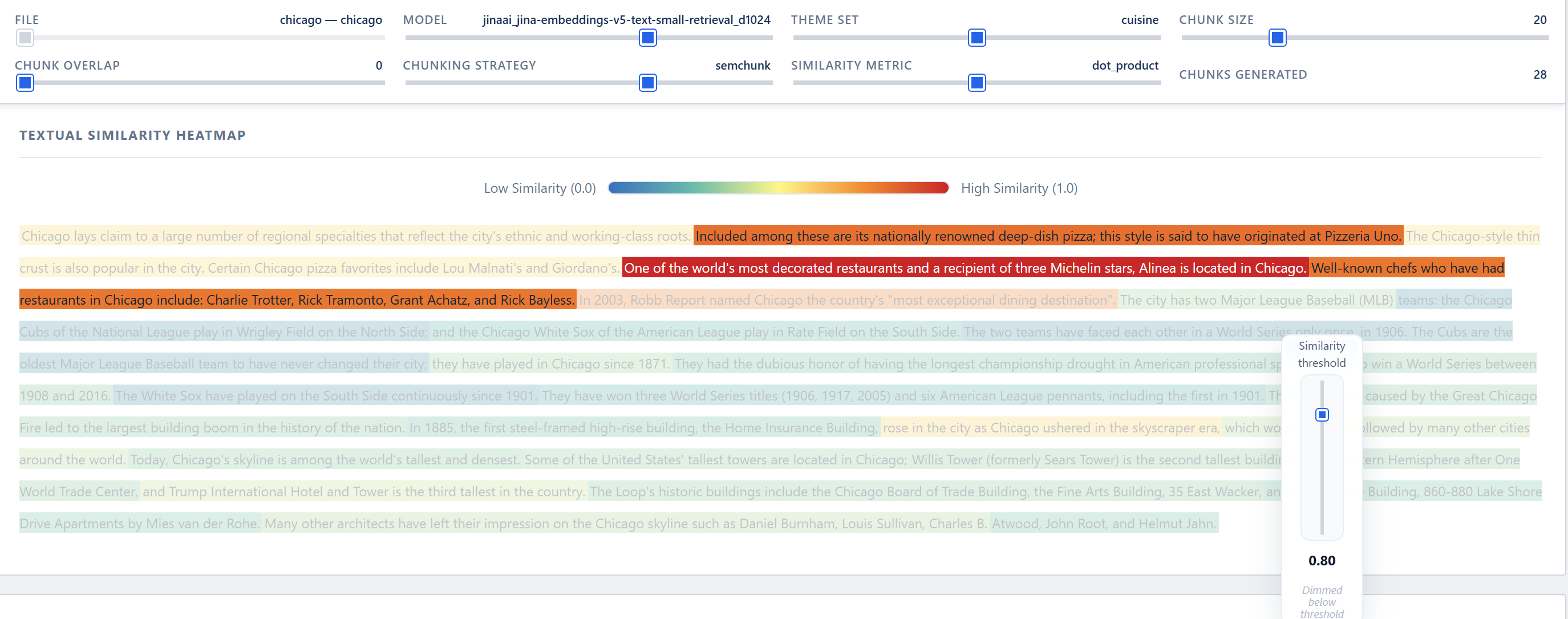
- Une heatmap textuelle interactive : le texte est apparent, découpé en chunks, chaque chunk est coloré (rouge = similarité élevée, bleu = faible), avec affichage de la valeur normalisée (0–1) au survol.
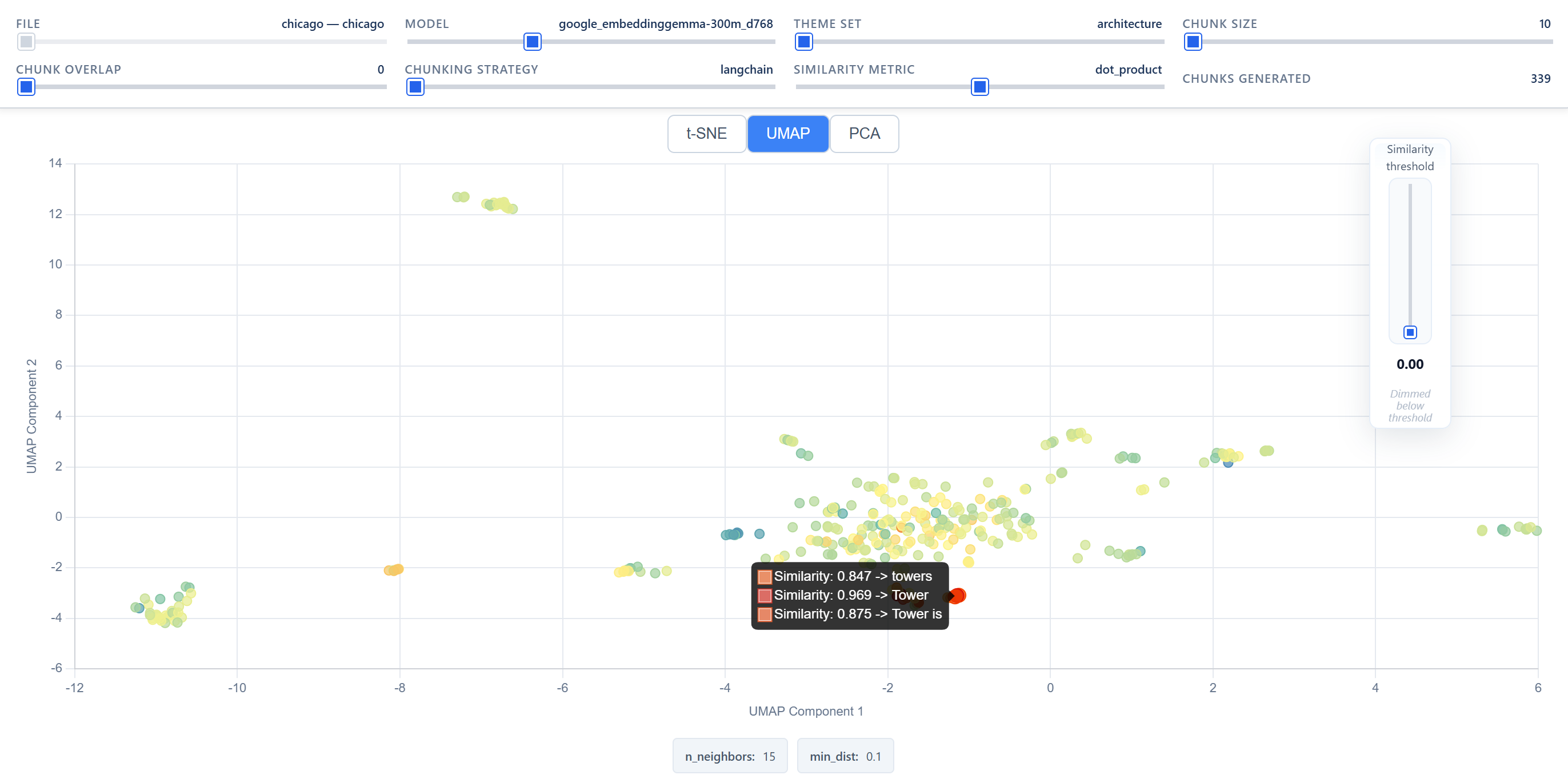
- Des projections 2D de l’espace d’embedding via t-SNE, UMAP ou PCA, avec séparation des chunks en deux clusters par seuil thématique.
- Les scores de silhouette intra- et inter-clusters ainsi que les temps d’exécution par combinaison.
Caractéristiques
- Interface en ligne de commande (CLI) :
forzaembed run --config config.yamlforzaembed report --db forzaembed.db --output report.html
- Multi-backends : sentence-transformers, HuggingFace, FastEmbed (multi-CPU/GPU), OpenAI, Mistral.
- Dédoublonnement intelligent : pour les chunkers basés sur des phrases (NLTK, spaCy), les segments identiques produits par variation de la taille de chunk ne sont pas ré-évalués.
- Cache SQLite : permet la reprise d’une exécution interrompue sans perte de données.
- Rapport HTML autonome : sans dépendance externe, partageable par courriel.
Exploitation pour le projet SmartWatch
ForzaEmbed a été utilisé pour optimiser le filtre sémantique de SmartWatch, une application de veille automatisée des horaires d’ouverture d’établissements publics. Plusieurs analyses ont été menées :
- Comparaison des sentencizers : L’analyse a montré que le découpage par caractères (raw) coupe les mots en deux, tandis que NLTK et semchunk respectent les limites de phrases. Semchunk s’est révélé le meilleur compromis entre granularité fine et cohérence sémantique.
- Étendue du vocabulaire thématique : Un seul mot-clé (“horaires d’ouverture”) s’est avéré moins discriminant qu’une liste de 20 à 64 expressions. La sélection du nombre de termes est un compromis entre sensibilité et spécificité.
- Choix de la métrique de similarité : Le produit scalaire normalisé génère un contraste plus marqué entre chunks pertinents et non pertinents que la similarité cosinus. Cette propriété est avantageuse pour un filtre par seuil.
- Sélection du modèle d’embedding : jina-embeddings-v3 (1024 dimensions) a constitué le meilleur compromis qualité/ressources, permettant une réduction de 40 % des tokens soumis au LLM.
Impact
ForzaEmbed fournit aux ingénieurs RAG un outil de mesure objectif pour structurer leurs phases de R&D :
- Disponibilité publique : distribué sous licence MIT.
- Optimisation des coûts et performances : l’outil a permis d’identifier, pour SmartWatch, une configuration locale légère (jina-embeddings + chunking semchunk + produit scalaire) offrant un pouvoir séparateur élevé, réduisant de 40 % le volume de tokens à traiter par le LLM et diminuant de fait le temps de réponse du cluster interne.
- Démonstrateur accessible : une application interactive est hébergée sur Hugging Face Spaces, présentant des benchmarks pré-calculés.
- Valeur pédagogique : la heatmap textuelle sert d’une part d’outil de présentation pour justifier des choix techniques auprès d’équipes non spécialistes, et constitue d’autre part un support efficace pour explorer des cas limites où les métriques classiques (score de silhouette) sont inopérantes (jeux de données de petite taille).