
Context
In Retrieval-Augmented Generation (RAG) pipelines, semantic filtering quality depends on multiple interdependent levers: text chunking strategy, embedding model, etc. Performance varies with document language, segment size, overlap rate, and the chosen similarity metric. The absence of systematic evaluation tools often leads to empirical architectural choices with no guarantee that the selected configuration is optimal. ForzaEmbed originated from this gap – it is a derived project from SmartWatch, where optimizing the semantic filter required building a dedicated evaluation framework.
Challenge
The objective was to design an automated tool capable of exhaustively exploring the hyperparameter space of embedding configurations and rendering results in a visually interpretable form. The expected deliverable was an open-source Python framework paired with an interactive HTML rendering engine, producing self-contained reports usable both by data scientists in R&D phases and by project teams needing to justify technical decisions.
Approach
The framework is structured as a Python CLI package organized in three main components:
-
Grid Search Space Generation: From a YAML configuration file, the tool computes the Cartesian product of all declared hyperparameters: embedding backends (sentence-transformers, FastEmbed, OpenAI, Mistral), chunking strategies (LangChain, raw, semchunk, NLTK, spaCy), segment sizes (up to 7 steps, from 10 to 1000 characters), overlap rates (0 to 200), similarity metrics (cosine, Euclidean, Manhattan, dot product, Chebyshev), and thematic keyword lists. Invalid combinations (e.g., overlap larger than chunk size) are automatically excluded.
-
Parallelized Execution with Persistent Cache: For each valid combination, the source text is segmented and embeddings are computed using the FastEmbed library – which natively supports multi-CPU/multi-GPU execution – complemented by a HuggingFace client for additional models. A local SQLite database acts as a persistent cache: each chunk is hashed and its vector stored, preventing redundant recomputation when varying external parameters (metric for instance). Segments are then evaluated for similarity against user-defined themes. With 7 chunk sizes × 7 overlaps × 5 strategies × 5 metrics × 3 themes × 8 models (≈21,000 combinations), this cache avoids massive recomputation.
-
Self-contained Rendering Engine: Results are compiled into a single HTML file. A floating, semi-transparent control bar lets users adjust hyperparameter sliders in real time. The report includes:
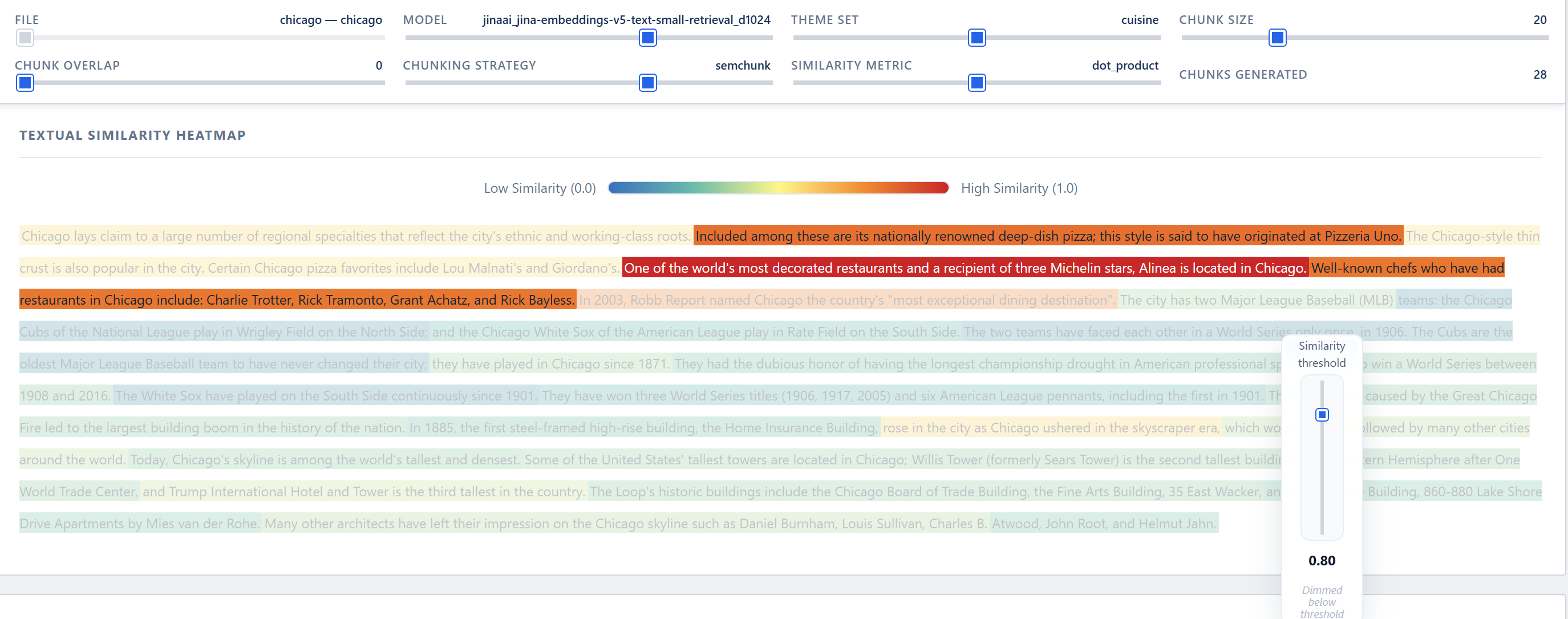
- An interactive textual heatmap: text is displayed as readable chunks, each colored by similarity (red = high, blue = low), with normalized scores (0–1) shown on hover.
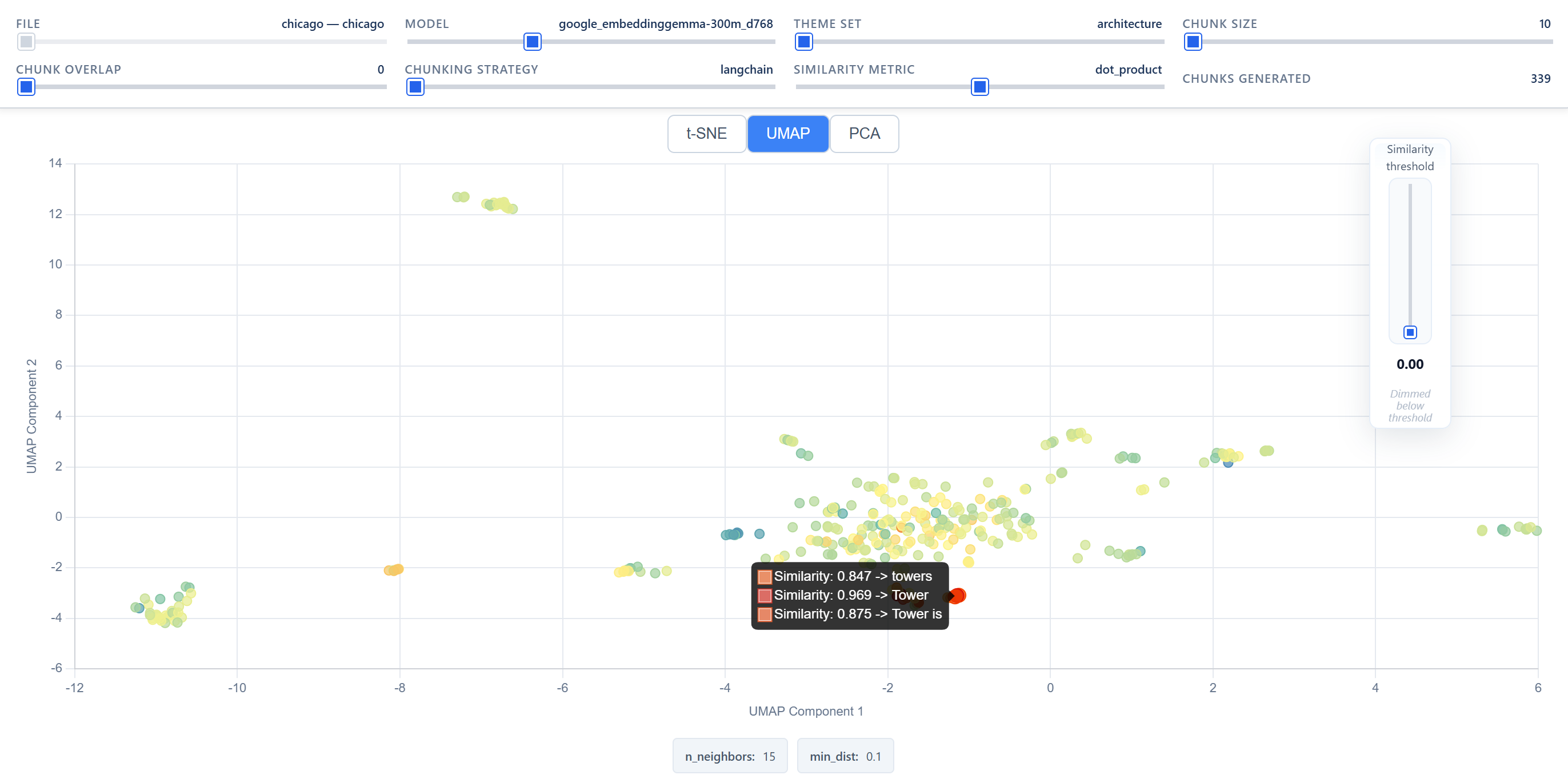
- 2D embedding space projections via t-SNE, UMAP or PCA, with chunk separation into two clusters based on a thematic threshold.
- Intra- and inter-cluster silhouette scores and execution time for each grid combination.
Features
- Command Line Interface (CLI) :
forzaembed run --config config.yamlforzaembed report --db forzaembed.db --output report.html
- Multi-backend support: sentence-transformers, HuggingFace, FastEmbed (multi-CPU/GPU), OpenAI, Mistral.
- Smart deduplication: for sentence-based chunkers (NLTK, spaCy), identical segments produced by varying chunk size are not re-evaluated.
- SQLite cache: allows resuming interrupted executions without data loss.
- Standalone HTML report: no external dependencies, shareable via email.
Exploitation for the SmartWatch Project
ForzaEmbed was used to optimize the semantic filter of SmartWatch, an automated monitoring application for public facility opening hours. Several analyses were conducted:
- Sentencizer comparison: character-based splitting (raw) breaks words arbitrarily, whereas NLTK and semchunk respect sentence boundaries. Semchunk proved the best trade-off between fine granularity and semantic coherence.
- Thematic vocabulary scope: a single keyword (“opening hours”) was less discriminant than a list of 20 to 64 expressions; selecting the right number of terms is a balance between sensitivity and specificity.
- Similarity metric selection: normalized dot product produces a sharper contrast between relevant and irrelevant chunks than cosine similarity – a desirable property for threshold-based filtering.
- Embedding model selection: Jina-embeddings-v3 (1024 dimensions) offered the best quality-to-resource ratio, reducing the volume of tokens submitted to the LLM by 40%.
Outcome
ForzaEmbed provides RAG engineers with a quantitative tool to structure their R&D phases:
- Public availability: released under the MIT license.
- Cost and performance optimization: the tool enabled the identification, for SmartWatch, of a lightweight local configuration (jina-embeddings + semchunk chunking + dot product similarity) delivering high separability, reducing by 40% the volume of tokens processed by the LLM and thereby decreasing the response latency of the internal cluster.
- Interactive demo: a live application is hosted on Hugging Face Spaces, presenting pre-computed benchmarks.
- Pedagogical value: the textual heatmap serves, on the one hand, as a presentation tool to explain technical decisions to non-specialist teams, and, on the other hand, as an effective tool for exploring edge cases where traditional metrics (such as the silhouette score) are ineffective (e.g., small datasets).