SmartWatch
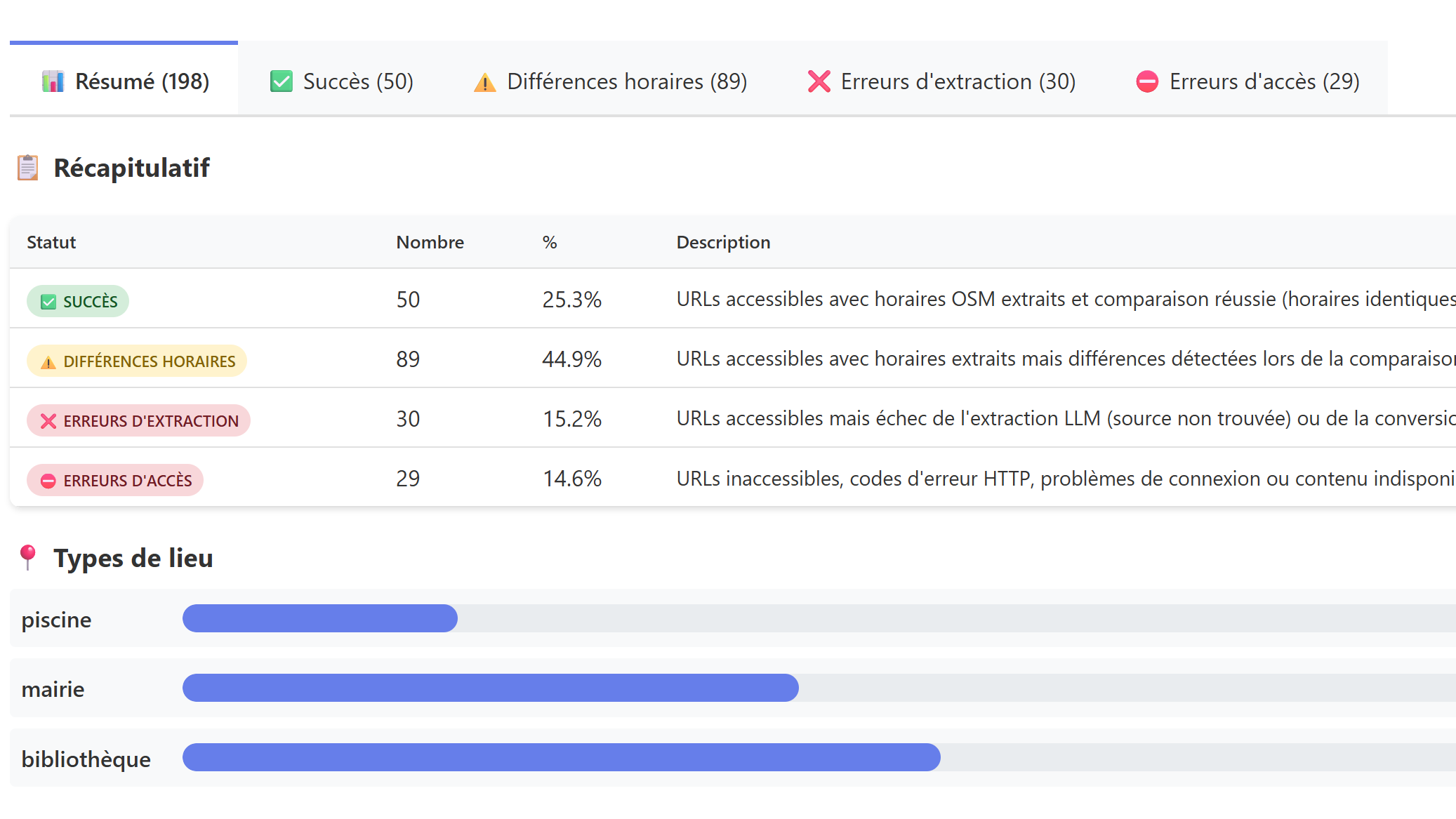
Pipeline de scraping des horaires d'établissements publics lyonnais. Exploite embeddings et LLM pour produire une sortie structurée et univoque, comparée à data.grandlyon.com.
Python LLM Web Scraping Embeddings NLP
Je conçois et déploie des solutions basées sur l'intelligence artificielle et l'analyse de données. Plus de 20 ans d'expérience, de l'ingénierie logicielle à la science des données, pour transformer des enjeux métier en applications robustes. Expert en NLP, LLM et pipelines de données, je mets un point d'honneur à allier rigueur scientifique et approche pédagogique.
Pipeline de scraping des horaires d'établissements publics lyonnais. Exploite embeddings et LLM pour produire une sortie structurée et univoque, comparée à data.grandlyon.com.

Pipeline Python de transcription audio local, avec diarisation des locuteurs, utilisable en temps réel (micro) ou sur fichier. Fonctionne sans accès internet après téléchargement des modèles.

Bibliothèque Python modulaire pour la correspondance de similarité de chaînes. Supporte distance d'édition, similarité de séquence, phonétique et sémantique avec une API unifiée.
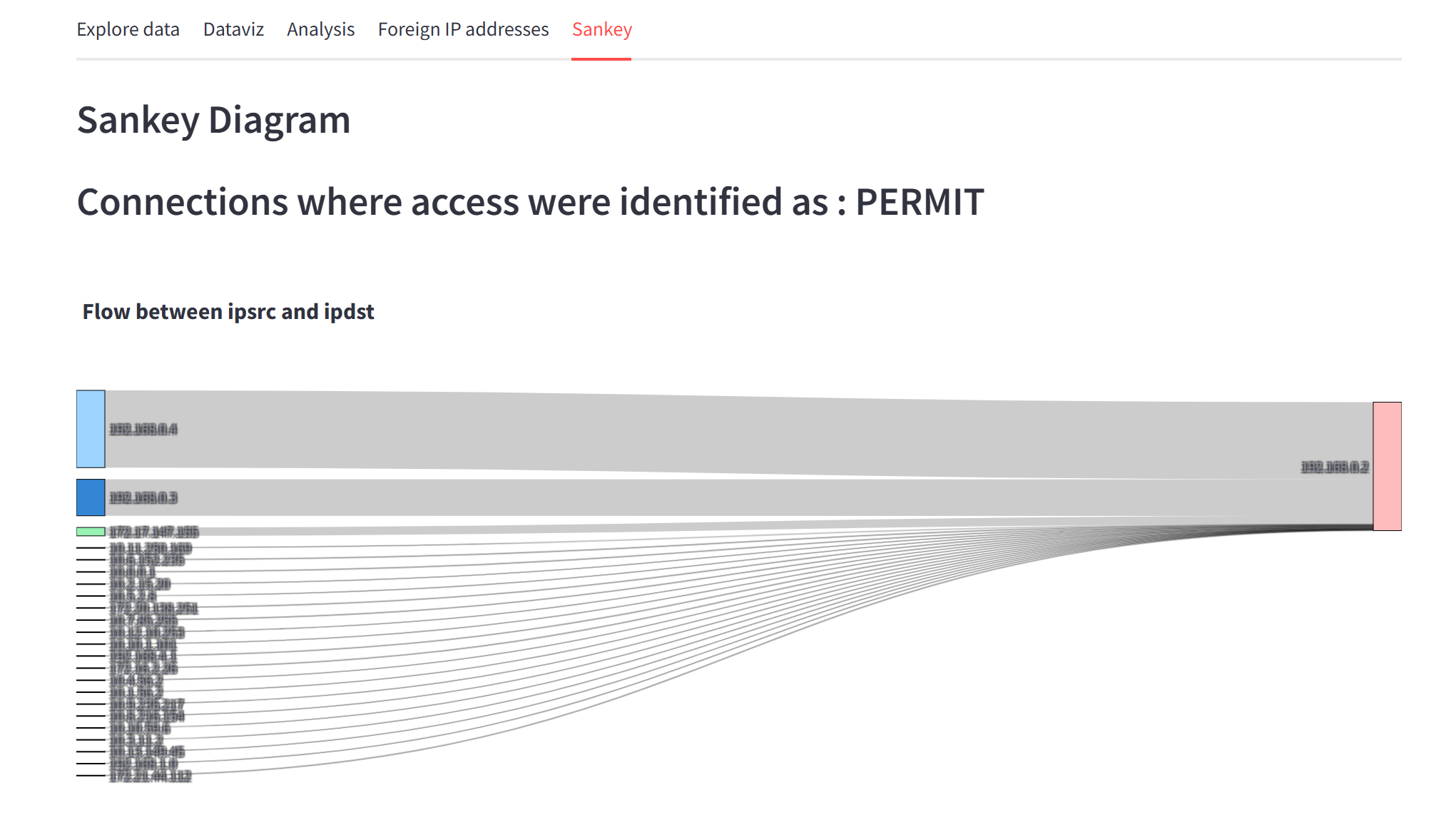
Plateforme d'analyse de logs par IA, utilisant le clustering et la détection statistique d'anomalies pour identifier des patterns dans les fichiers de logs.
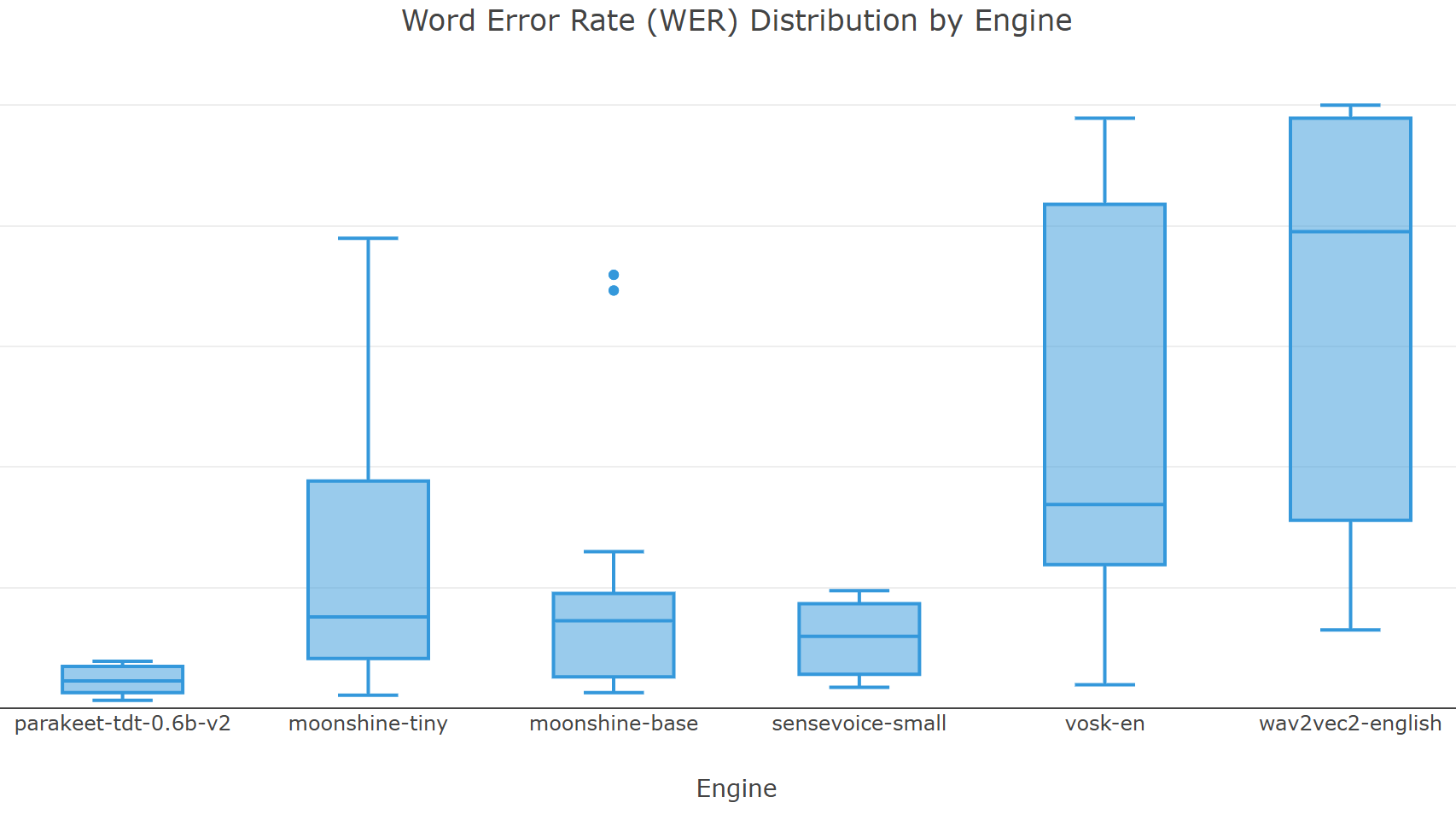
Plateforme de benchmarking pour systèmes de reconnaissance automatique de la parole : dégradation audio contrôlée, enhancement, normalisation et comparaison multi-moteurs avec rapports interactifs.

Framework Python de benchmarking pour modèles d'embedding textuel : grid search sur les stratégies de chunking et métriques de similarité, avec heatmap textuelle et visualisations des espaces d'embeddings.
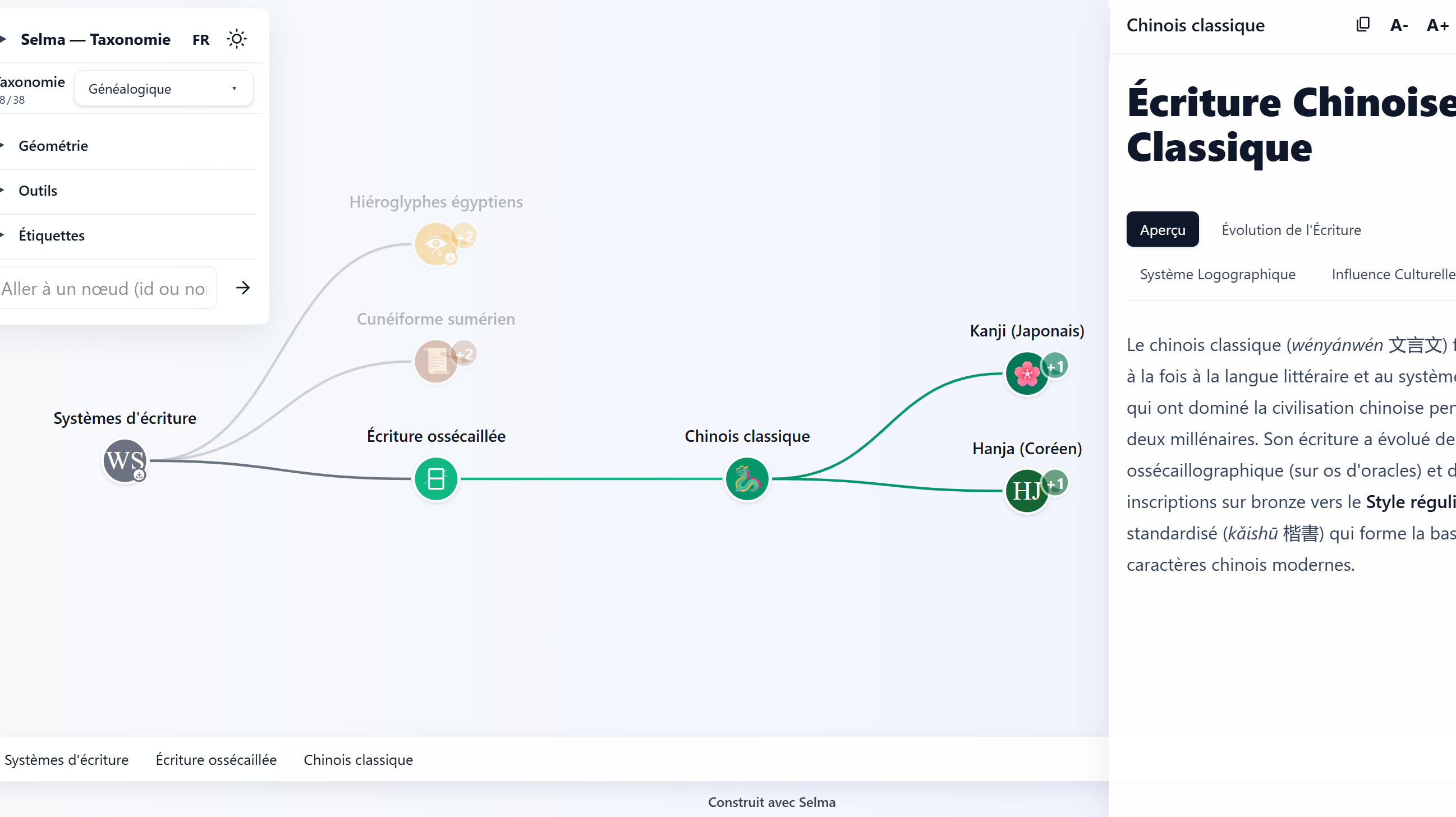
Template TypeScript pour visualiser et explorer interactivement des structures de données hiérarchiques.
Visualisations interactives pour explorer les concepts de statistique et d'apprentissage automatique.