NLP & RAG
SmartWatch
Stable
juin 2025
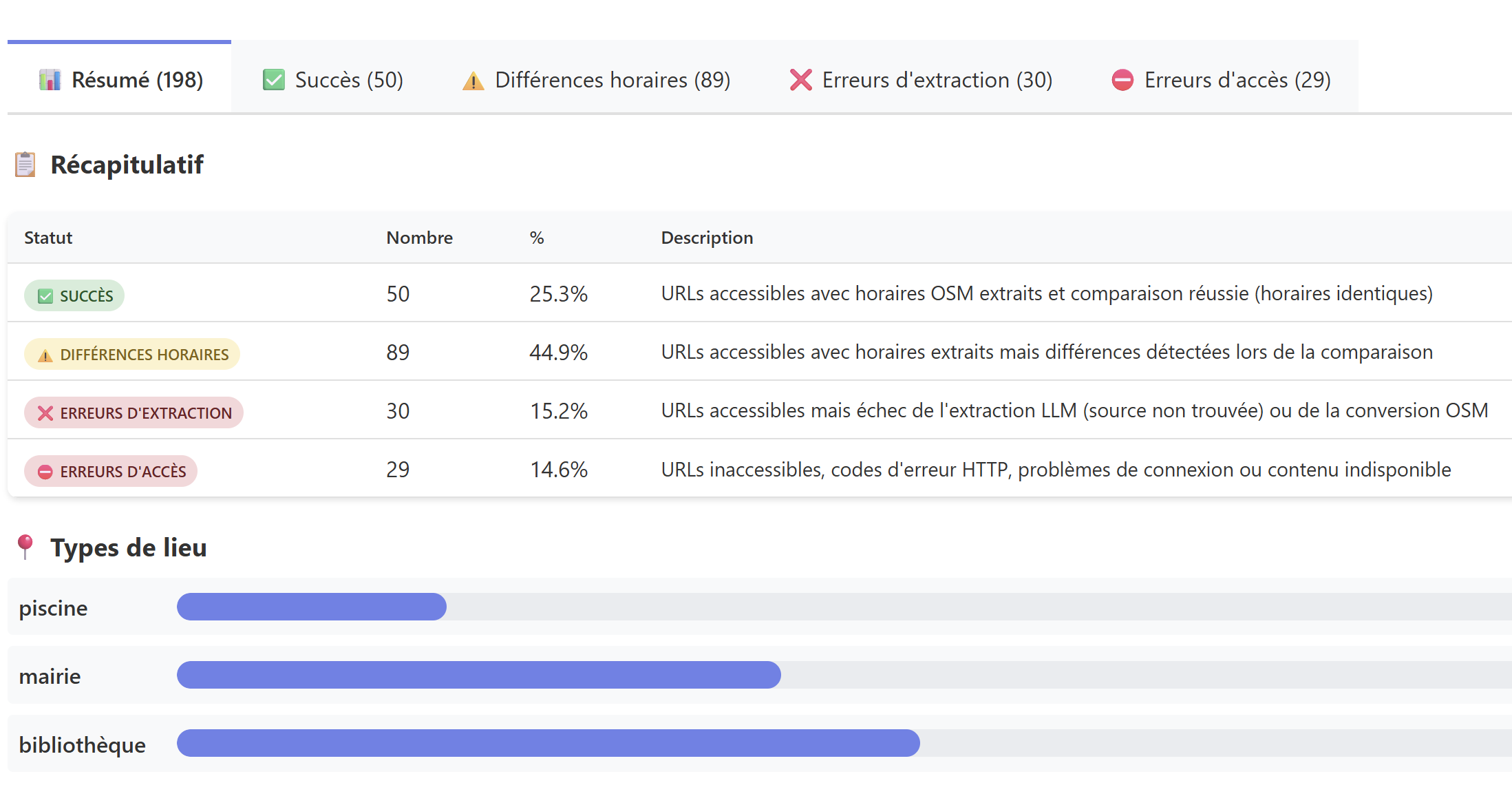
Pipeline d'automatisation de mise à jour pour data.grandlyon.com. Exploite embeddings et LLM pour produire une sortie structurée et univoque.
Python LLM Web Scraping Embeddings NLP
Data Scientist & Ingénieur IA
Je conçois et déploie des applications IA, du cadrage à la mise en production. Vingt-deux ans d'ingénierie et une solide pratique de la donnée. Je combine rigueur technique, ancrage métier et sens de la pédagogie.
Quelques réalisations qui résument ma pratique :
Pipeline d'automatisation de mise à jour pour data.grandlyon.com. Exploite embeddings et LLM pour produire une sortie structurée et univoque.

Framework Python de benchmarking pour modèles d'embedding textuel : grid search sur les stratégies de chunking et métriques de similarité, avec heatmap textuelle et visualisations des espaces d'embeddings.
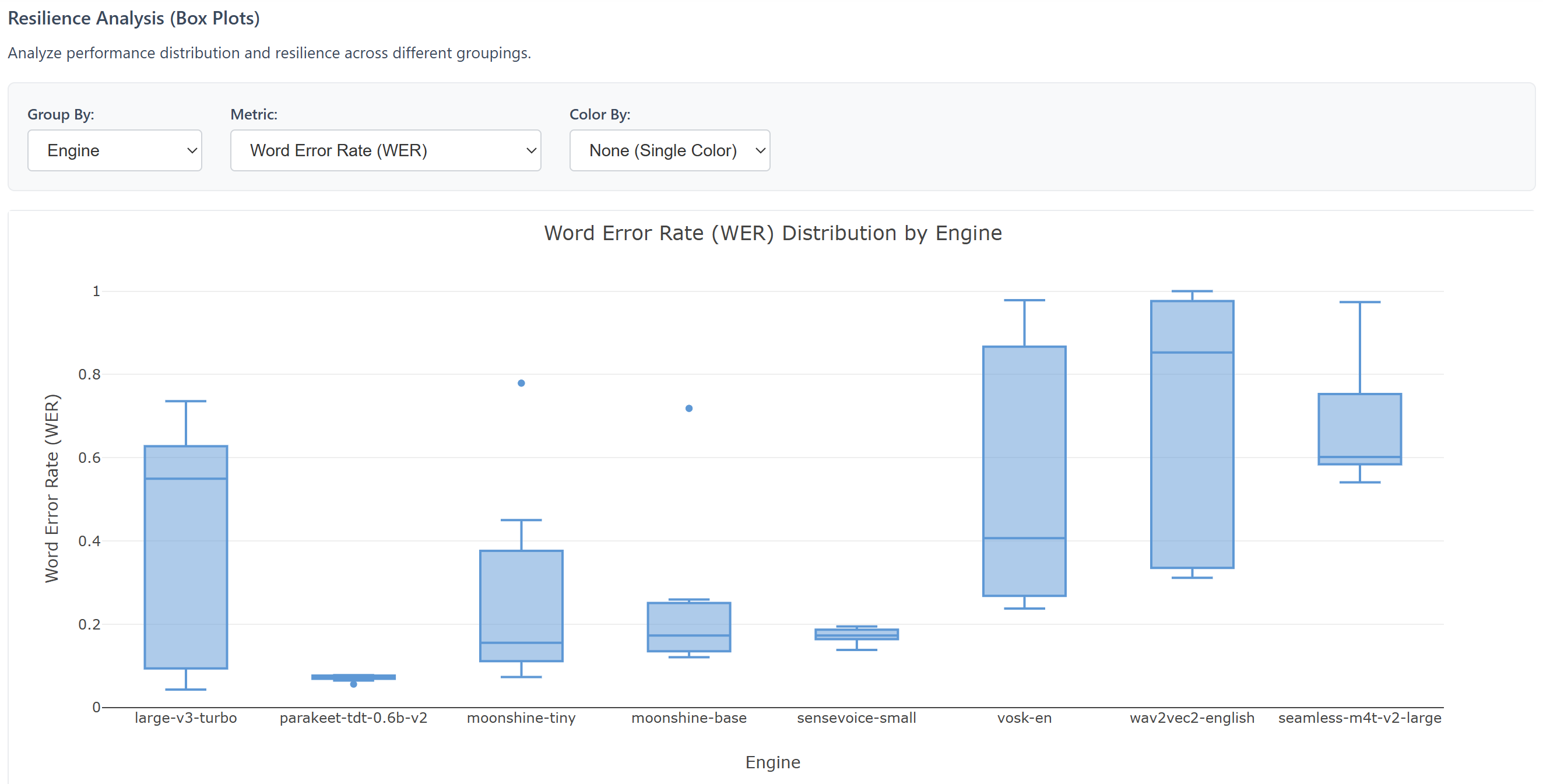
Plateforme d'évaluation comparative pour les systèmes de reconnaissance vocale automatique : dégradation, amélioration et normalisation contrôlées du signal audio, ainsi que comparaison entre plusieurs moteurs; avec des rapports interactifs.
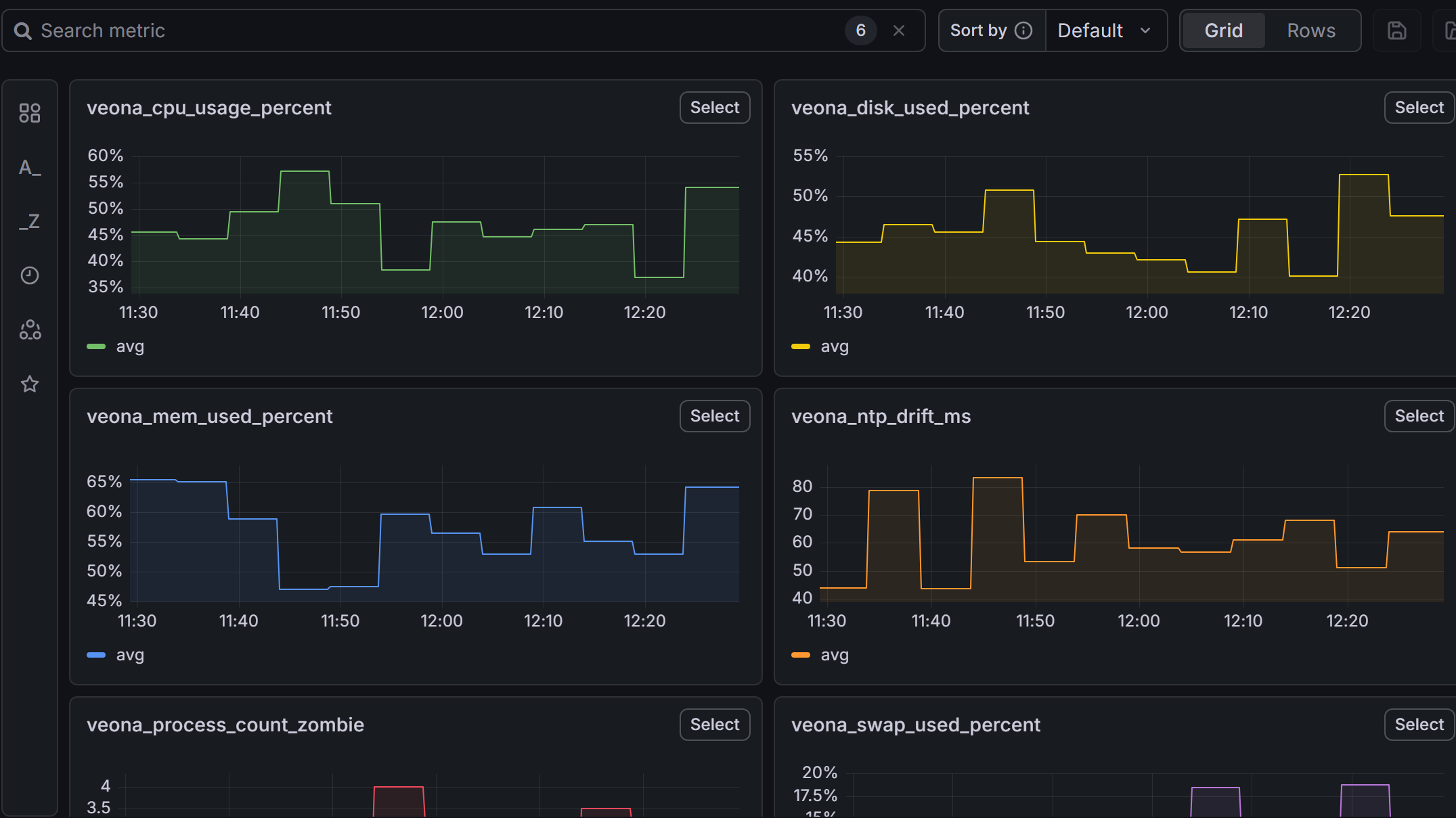

Pipeline Python de transcription audio local, avec diarisation des locuteurs, utilisable en temps réel (micro) ou sur fichier. Fonctionne sans accès internet après téléchargement des modèles.
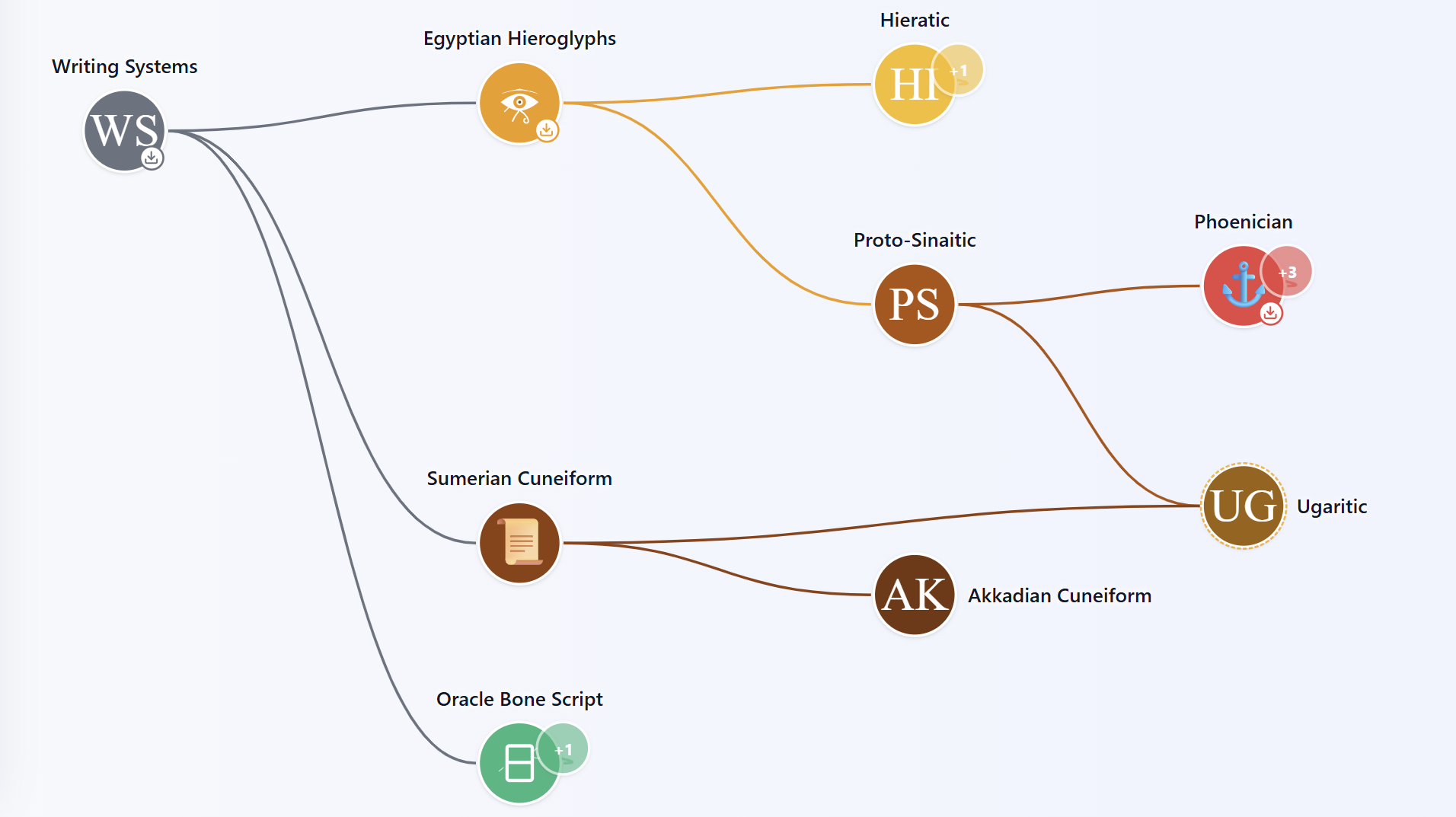
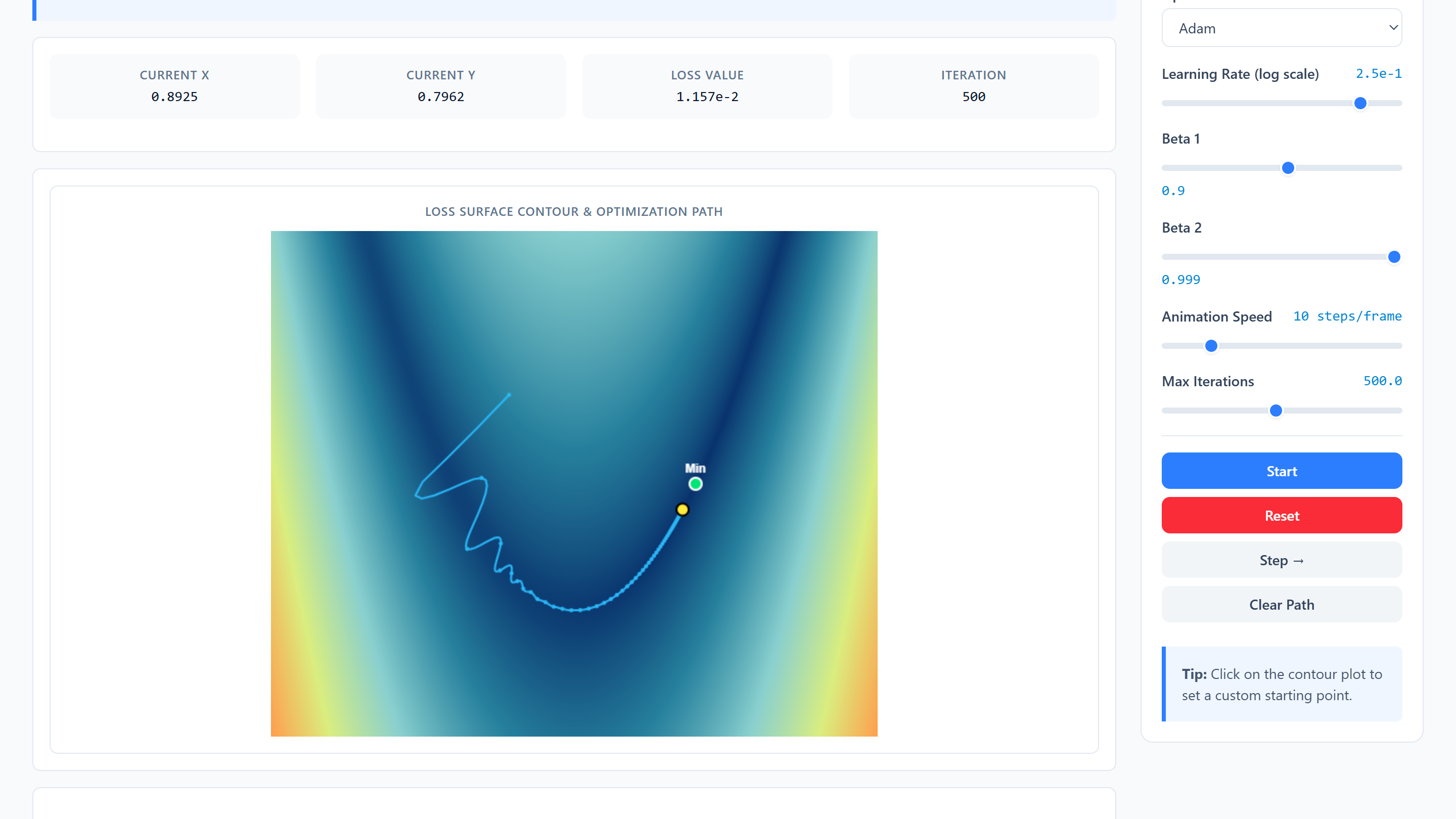
Visualisations interactives pour explorer les concepts de statistiques et d'apprentissage automatique.
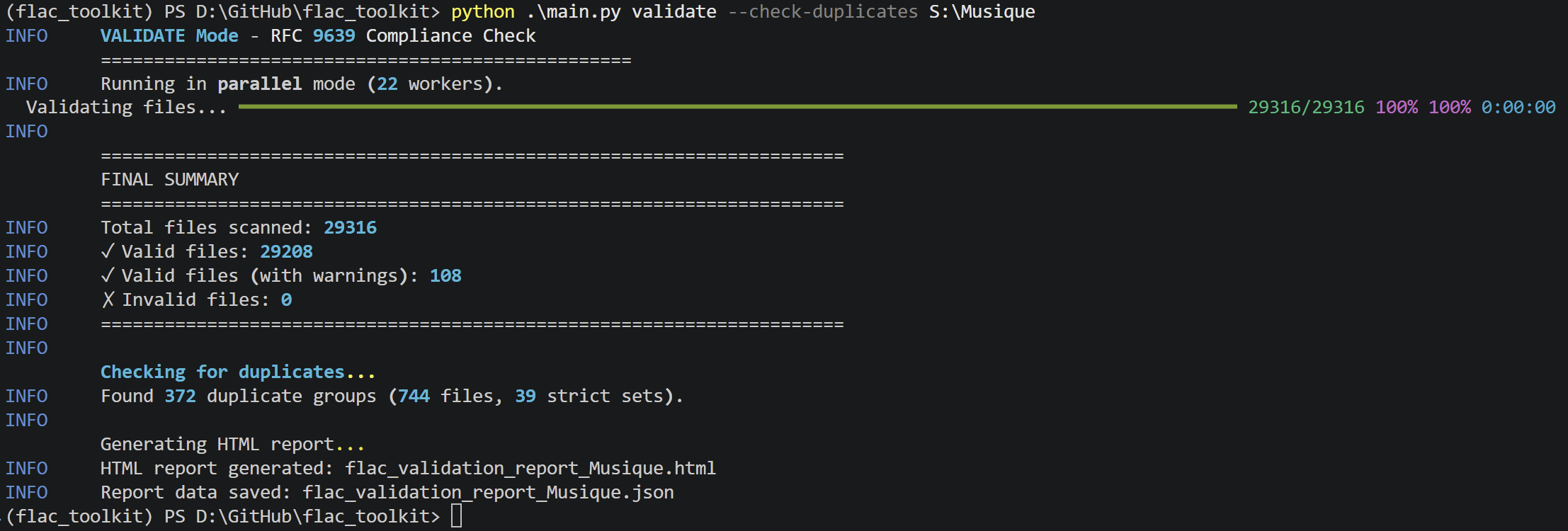
Un utilitaire en ligne de commande pour la validation de bas niveau, la réparation automatisée, la détection de doublons audio et la normalisation ReplayGain de fichiers FLAC.

Co-conception et animation d'ateliers de formation à l'IA. Production de ressources pédagogiques (livret de prompting, manuel de l'animateur) pour les agents de la Métropole de Lyon.
Retrouvez ci-dessous mes différents réseaux professionnels, mes coordonnées ainsi que mon CV interactif.